If you’re diving into cloud data integration, Azure Data Factory is a game-changer. This powerful ETL service simplifies how you move, transform, and orchestrate data across cloud and on-premises sources—without writing a single line of code. Let’s explore why it’s essential.




What Is Azure Data Factory?

Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service that allows organizations to create data-driven workflows for orchestrating and automating data movement and data transformation. It enables you to build complex ETL (Extract, Transform, Load) pipelines using a visual interface, making it accessible for both developers and non-technical users.
Core Purpose and Vision
The primary goal of Azure Data Factory is to help businesses integrate data from disparate sources, transform it into meaningful insights, and deliver it to analytical systems like Power BI, Azure Synapse Analytics, or data warehouses. Unlike traditional ETL tools that require heavy infrastructure, ADF runs entirely in the cloud, offering scalability and flexibility.
- Enables hybrid data integration across cloud and on-premises systems.
- Supports both code-based and no-code pipeline development.
- Integrates seamlessly with other Azure services like Azure Blob Storage, Azure SQL Database, and Azure Databricks.
“Azure Data Factory is not just a tool; it’s a platform for building intelligent data pipelines at scale.” — Microsoft Azure Documentation
How It Fits in the Modern Data Stack
In today’s data-driven world, companies collect information from CRM systems, IoT devices, social media, and more. Azure Data Factory acts as the central nervous system that connects these data sources, cleanses the data, and prepares it for analytics. It’s especially valuable in modern data architectures like data lakes and lakehouses.
For example, a retail company might use ADF to pull sales data from multiple stores (on-premises databases), combine it with online transaction data (from Azure SQL), and load it into Azure Synapse for real-time reporting. This entire process can be automated and scheduled using ADF pipelines.
Learn more about its role in enterprise data integration at Microsoft’s official Azure Data Factory documentation.
Key Components of Azure Data Factory
To fully understand how Azure Data Factory works, you need to know its core components. These building blocks form the foundation of every data pipeline you create.
Pipelines and Activities
A pipeline in Azure Data Factory is a logical grouping of activities that perform a specific task. For instance, a pipeline might extract customer data from Salesforce, transform it using Azure Databricks, and load it into a data warehouse.
- Copy Activity: Moves data from source to destination with high throughput and built-in fault tolerance.
- Transformation Activities: Includes HDInsight Hive, Spark, Data Lake Analytics, and custom .NET activities.
- Control Activities: Used to manage workflow logic—like If Condition, ForEach, and Execute Pipeline.
Each activity can be configured with parameters, dependencies, and error handling rules, allowing for robust and reusable workflows.
Linked Services and Datasets
Linked Services define the connection information needed to connect to external resources. Think of them as connection strings that specify the endpoint, authentication method, and network settings.
- Examples include Azure Blob Storage, SQL Server, Oracle, Amazon S3, and REST APIs.
- They support secure credential storage via Azure Key Vault.
Datasets, on the other hand, represent the structure and location of data within a linked service. For example, a dataset might point to a specific CSV file in a Blob Storage container or a table in Azure SQL Database.
“Without linked services and datasets, pipelines wouldn’t know where to get or send data.” — Azure Architecture Center
Integration Runtime (IR)
The Integration Runtime is the backbone of data movement and transformation in ADF. It’s a managed compute infrastructure that provides the following capabilities:
- Azure IR: For cloud-to-cloud data transfer.
- Self-Hosted IR: Enables connectivity to on-premises data sources securely.
- SSIS IR: Runs legacy SQL Server Integration Services packages in the cloud.
The Self-Hosted IR is particularly useful when dealing with firewalled databases or internal ERP systems like SAP. It acts as a bridge between your private network and the Azure cloud, ensuring secure and reliable data transfer.
Why Choose Azure Data Factory Over Other Tools?
With so many ETL and data integration tools available—like Informatica, Talend, and AWS Glue—why should you choose Azure Data Factory? The answer lies in its native integration, scalability, and cost-efficiency within the Microsoft ecosystem.
Seamless Integration with Azure Ecosystem
One of the biggest advantages of Azure Data Factory is its deep integration with other Azure services. Whether you’re using Azure Data Lake Storage, Azure Synapse Analytics, Azure Machine Learning, or Power BI, ADF connects effortlessly.
- Automatically authenticate using Managed Identities or Azure Active Directory.
- Trigger machine learning models in Azure ML as part of a pipeline.
- Push transformed data directly into Power BI datasets for real-time dashboards.
This tight coupling reduces configuration overhead and enhances security by minimizing the need for external credentials.
Serverless Architecture and Scalability
Unlike traditional ETL tools that require provisioning and managing servers, Azure Data Factory is serverless. You don’t have to worry about CPU, memory, or disk space. The platform automatically scales based on workload demands.
For example, if you’re processing 10 GB of data daily, ADF uses minimal resources. But if you suddenly need to process 1 TB due to a marketing campaign, it scales up instantly without any manual intervention.
This elasticity makes it ideal for organizations with fluctuating data volumes. You only pay for what you use, which aligns perfectly with cloud cost optimization strategies.
“Serverless doesn’t mean powerless—it means freedom from infrastructure management.” — Cloud Computing Best Practices
Visual Development and Low-Code Experience
Not everyone on your team is a developer. Azure Data Factory offers a drag-and-drop interface called the Data Factory UX (user experience), which allows business analysts and data engineers to build pipelines visually.
- Drag sources, transformations, and sinks onto a canvas.
- Configure settings using intuitive forms instead of code.
- Preview data at each step to validate transformations.
For advanced users, ADF also supports JSON-based pipeline definitions and Git integration for version control, enabling DevOps practices in data engineering.
Explore the visual authoring experience here: Azure Data Factory Copy Data Tool Tutorial.
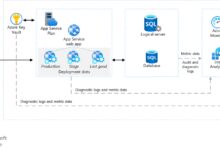
Building Your First Pipeline in Azure Data Factory
Now that you understand the basics, let’s walk through creating a simple pipeline that copies data from Azure Blob Storage to Azure SQL Database. This hands-on example will solidify your understanding of ADF’s workflow.
Step 1: Set Up Your Azure Environment
Before creating a pipeline, ensure you have the necessary resources in your Azure subscription:
- An Azure Storage account with a container holding sample data (e.g., a CSV file).
- An Azure SQL Database with a table to receive the data.
- Azure Data Factory instance (create one via the Azure portal).
Make sure you have Contributor access to these resources so you can configure connections and deploy pipelines.
Step 2: Create Linked Services
Navigate to your Data Factory in the Azure portal and open the Author & Monitor interface. From there:
- Go to the ‘Manage’ tab and select ‘Linked services’.
- Create a new linked service for Azure Blob Storage by selecting your storage account and authenticating via account key or managed identity.
- Repeat the process for Azure SQL Database, providing server name, database name, and authentication details.
These linked services will be referenced later when defining datasets.
Step 3: Define Datasets and Build the Pipeline
Next, define the source and sink datasets:
- Create a dataset pointing to your CSV file in Blob Storage.
- Create another dataset for the target SQL table.
- Set data types and schema appropriately (ADF can auto-detect schema in many cases).
Then, create a new pipeline:
- Add a ‘Copy Data’ activity.
- Set the source dataset to the Blob Storage CSV.
- Set the sink dataset to the SQL table.
- Configure mapping if column names differ.
Finally, publish your changes and trigger the pipeline manually to test it.
“The first pipeline is always the hardest—but also the most rewarding.” — Data Engineer’s Journal
Advanced Capabilities: Beyond Basic ETL
While basic data movement is powerful, Azure Data Factory truly shines when you leverage its advanced features for complex data workflows.
Control Flow and Conditional Logic
Real-world data pipelines are rarely linear. You often need to make decisions based on data conditions. ADF supports control flow activities like:
- If Condition: Execute different paths based on a boolean expression.
- Switch Case: Route execution based on multiple values.
- Wait Activity: Pause execution for a specified time (useful for rate-limited APIs).
- Until Loop: Repeat an activity until a condition is met.
For example, you could build a pipeline that checks if a file exists in Blob Storage. If it does, process it; otherwise, send an alert via Logic Apps.
Parameterization and Reusability
To avoid duplicating pipelines, ADF allows you to parameterize almost every component:
- Pipeline parameters can accept values at runtime (e.g., date range, file path).
- Dataset parameters enable dynamic file naming (e.g.,
sales_{date}.csv). - Global parameters allow sharing values across pipelines.
This makes your pipelines reusable and adaptable to different scenarios without rewriting logic.
Custom Activities with Azure Functions or Databricks
When built-in activities aren’t enough, you can extend ADF with custom code. Use:
- Azure Functions: Run small, event-driven scripts (e.g., validate JSON, send notifications).
- Azure Databricks: Perform advanced analytics or machine learning transformations.
- HDInsight: Process big data with Hadoop or Spark clusters.
These integrations turn ADF into a central orchestrator for a wide range of data processing engines.
Learn how to integrate with Databricks: Run a Databricks Notebook with ADF.
Monitoring, Security, and Governance
Once your pipelines are running, monitoring and securing them becomes critical. Azure Data Factory provides robust tools for observability and compliance.
Monitoring with Azure Monitor and Pipeline Runs
The Monitor tab in ADF gives you real-time visibility into pipeline executions:
- View success/failure status, duration, and input/output details.
- Set up alerts using Azure Monitor for failed runs or long durations.
- Analyze logs with Log Analytics for deeper troubleshooting.
You can also use the REST API or PowerShell to programmatically check pipeline status, enabling integration with external monitoring systems.
Role-Based Access Control (RBAC) and Security
Security is paramount when handling sensitive data. ADF supports:
- Azure AD authentication for user and service principal access.
- Managed Identities to eliminate credential storage in linked services.
- Private Endpoints to secure data factory endpoints within a VNet.
- Integration with Azure Key Vault for secrets management.
By leveraging RBAC, you can assign roles like Data Factory Contributor, Reader, or Operator to control who can create, view, or run pipelines.
“Security isn’t an add-on—it’s built into every layer of Azure Data Factory.” — Microsoft Security Whitepaper
Data Lineage and Compliance
For regulatory compliance (e.g., GDPR, HIPAA), understanding data lineage is crucial. While native lineage in ADF is limited, you can integrate with:
- Azure Purview for end-to-end data governance and lineage tracking.
- Custom logging to track data transformations across pipelines.
- Audit logs via Azure Monitor for compliance reporting.
These capabilities help you answer questions like: Where did this data come from? Who accessed it? How was it transformed?
Best Practices for Optimizing Azure Data Factory
To get the most out of Azure Data Factory, follow these proven best practices for performance, cost, and maintainability.
Optimize Copy Activity Performance
The Copy Activity is the most used component in ADF. To maximize its efficiency:
- Use PolyBase for large-scale loads into Azure SQL Data Warehouse.
- Enable compression (e.g., GZIP) when moving large files.
- Adjust the number of integration runtime nodes for parallel processing.
- Use staging (Azure Blob or ADLS Gen2) when copying between incompatible sources.
Microsoft provides a performance tuning guide with detailed benchmarks and recommendations.
Implement CI/CD with Git and DevOps
Treat your data pipelines like code. Use:
- Git integration in ADF for version control.
- Branching strategies (e.g., dev, test, prod) to manage changes.
- Azure DevOps or GitHub Actions to automate deployment across environments.
This ensures consistency, enables rollback, and supports team collaboration.
Use Global Parameters and Templates
To standardize configurations across pipelines:
- Create global parameters for environment-specific values (e.g., storage account names).
- Use ARM templates or JSON exports to deploy ADF resources programmatically.
- Leverage pipeline templates for common patterns (e.g., daily extract, error handling).
These practices reduce errors and accelerate development.
Real-World Use Cases of Azure Data Factory
Understanding theoretical concepts is important, but seeing how Azure Data Factory is used in real scenarios brings clarity. Here are three industry examples.
Retail: Unified Customer Analytics
A multinational retailer uses ADF to combine data from:
- Point-of-sale systems (on-premises SQL Server).
- E-commerce platforms (REST APIs).
- Customer loyalty programs (Azure Cosmos DB).
ADF pipelines run hourly to consolidate this data into a data lake, where machine learning models predict customer churn and recommend personalized offers.
Healthcare: Secure Patient Data Integration
A hospital network uses ADF with Self-Hosted IR to extract anonymized patient records from legacy systems behind firewalls. The data is encrypted in transit, transformed to meet HL7 standards, and loaded into Azure Synapse for clinical analytics—ensuring HIPAA compliance.
Finance: Real-Time Fraud Detection
A bank uses ADF to ingest transaction data from ATMs and online banking systems. Pipelines trigger Azure Functions to score transactions for fraud risk in near real-time. Suspicious activities are flagged and sent to a case management system via Logic Apps.
“In finance, milliseconds matter—and Azure Data Factory helps us act fast.” — CTO, Global Bank
These examples show how versatile and mission-critical ADF can be across industries.
What is Azure Data Factory used for?
Azure Data Factory is used for orchestrating and automating data movement and transformation workflows in the cloud. It enables ETL/ELT processes, integrates data from multiple sources, and supports hybrid scenarios with on-premises systems via Self-Hosted Integration Runtime.
Is Azure Data Factory a PaaS or SaaS?
Azure Data Factory is a Platform-as-a-Service (PaaS) offering. It provides a managed platform for building data integration solutions without managing underlying infrastructure, though users configure and control the pipelines and resources.
How much does Azure Data Factory cost?
ADF uses a pay-as-you-go pricing model based on pipeline activity runs, data movement, and integration runtime usage. There’s a free tier with limited monthly activity, making it cost-effective for small to large-scale operations. Detailed pricing is available on the official Azure pricing page.
Can Azure Data Factory replace SSIS?
Yes, Azure Data Factory can replace many SSIS workloads, especially with the SSIS Integration Runtime that allows migration of existing SSIS packages to the cloud. However, for highly complex, component-heavy SSIS packages, a phased migration may be necessary.
How does ADF integrate with Power BI?
Azure Data Factory can load transformed data into datasets used by Power BI. While ADF doesn’t directly trigger Power BI refreshes, it can invoke Azure Functions or Logic Apps to programmatically refresh Power BI datasets after data loads.
From its intuitive visual interface to powerful orchestration capabilities, Azure Data Factory stands out as a must-have tool for modern data integration. Whether you’re moving data from legacy systems or building real-time analytics pipelines, ADF provides the flexibility, scalability, and security needed to succeed in the cloud era. By mastering its components, leveraging best practices, and understanding real-world applications, you can unlock the full potential of your data ecosystem.
Further Reading:



